filipjakobsen
31 Aug '17


Description
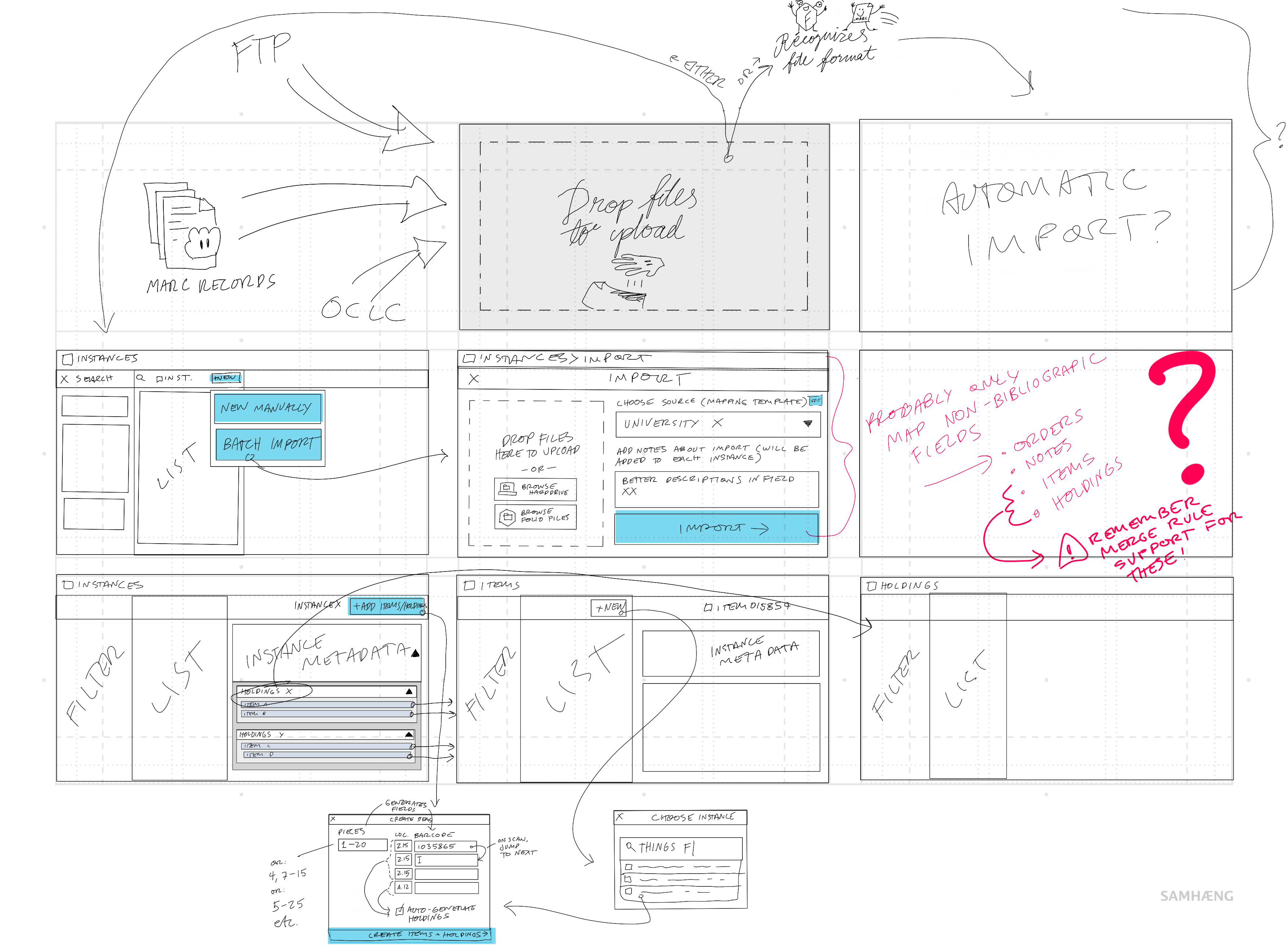
All of our imports are a marriage between MarcEdit and our ILS (OLE), with MarcEdit doing the bulk of the work. There are times when OLE can’t do what I need it to, particularly in the area of identifying “like” records. For example, we put all of our eBooks that are from multiple platforms, but are the same title, on the same record. I end up writing SQL queries to pre-identify matches, before the import. This is where I believe a system, well programmed, should be able to do a better job for the user.
Our discovery layer, VuFind, must always be considered. Since our MARC fields dictate the accuracy of everything about the discovery layer, we have to be consistent with the records. With FOLIO, and the introduction of different extractions of the incoming records into a CODEX, my thinking is that what drives the elements in the discovery layer that our patrons see will be different.
Processes
Attached is a table of MarcEdit tasks that we use regularly, how they couple up with OLE import profiles, and the work I wish the system would do. There are many more MarcEdit tasks then there are import profiles. One import profile can handle files that come from many of the MarcEdit tasks. OLE could do some of the editing that we do in MarcEdit, like add constant data, and delete fields, but if I even need to do something in MarcEdit once, that means I have the program open, and I may as well add everything to the “task” or macro I can there. Another benefit is that once the MarcEdit task is created and it is coupled with an import profile, anyone on the staff can handle just about any situation. We need workflows that allow the work to be simplified and repetitive at some point, so it can be completed by numerous people with various levels of skill.
As I said on the call, what the system needs to be good at is identifying matches and knowing then what to do about this match. If the system detects a match in a title should it:
I realize I’m speaking in terms of my current environment, but it does look like we are heading in the bib/holding/item direction in FOLIO. Under what circumstances each level (bib/holding/item) will be created will be important. The system’s ability to merge or not merge at the bib, holding, and item levels is crucial to keeping the catalog/database up to date efficiently.
LehighUniversity_batchimport.pdf (202.9 KB)

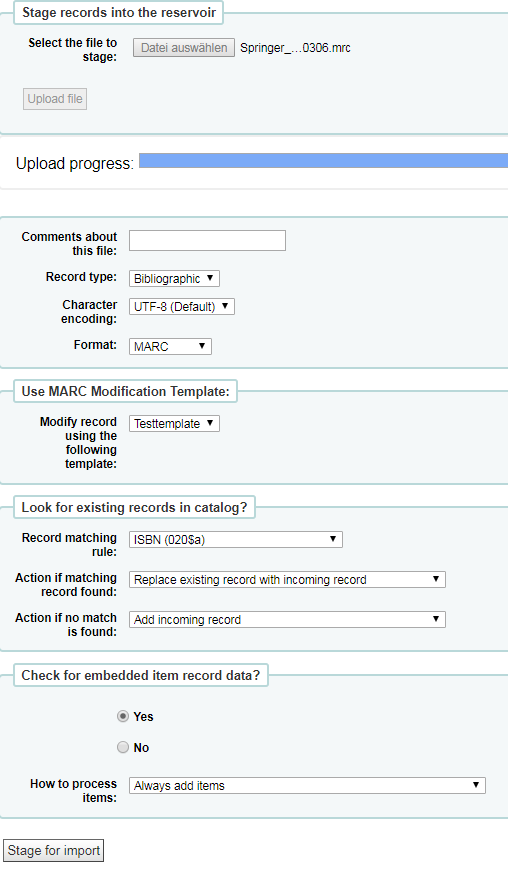
Maybe it will help us in our work if we look at how existing systems handle the import. I’d like to demonstrate how to import MARC records into Koha.
First, you have to define if it’s a bibliographic or authority record. Koha allows you to import either MARC or MARCXML data. The modification templates are used to make certain changes to the data according to defined criteria. For instance, copy field xxx to field yyy if field zzz matches “string”.
If you’d like to check for existing records in the database and merge them with the incoming records, you would define a record matching rule in the system preference. In this case the system checks for ISBN in 020$a. The match threshold is 1000 and an ISBN match counts 1000 points. If a matching record is found, the system can perform various operations. E.g. replace the existing record with the incoming record or ignore the incoming and just process the items. It’s also possibly to check for embedded item data (MARC 852).
However, before importing the records, MarcEdit must be used to evaluate the quality of the data.


Sorry, this isn’t displaying as I hoped it would. The attached document illustrates some of our record loading workflows.
record loading examples 20170831.pdf (181.8 KB)
HI Filip-
At NCSU, we use a variety of importing methods:
manual single title / small batch importing of bibs & creation of item records for items in hand
automated batch imports of bib & creation of order/call#&item from YBP
automated batch imports of invoice records with bib record overlay & order record update from YBP
manual batch imports of bibs & creation of call#/item records from Serials Solutions, Vendor supplied records
manual batch update/delete of bibs from Serials Solutions
For most batch imports of Vendor supplied records, we use MarcEdit to edit/cleanup records in bulk
For batch imports from suppliers, we have TechSpecs set up at their end so that the record edits/cleanup are done at their end & we don’t have to do much intervention.
I think the important thing to note is that we rely on the bib record import process & local system (Sirsi) to automatically create many/most of the records (call#/item/order & indirectly invoice) that are connected to the bib, and that being able to identify the matching rules and behavior for when records are loaded is critical.
Lynn

HI Filip-
It sounds like our import processes at Duke are similar to those at NCSU. While we do use MARCedit for smaller batches of vendor records, we do not always use it. We also have TechSpecs set up at some vendors where they clean up/manipulate metadata/normalize fields based on our requirements. These are larger files of MARC records, generally speaking, which are split into “new”, “delete” and “update” files. Our current system, Aleph, is set to update, add, or delete records based on our criteria.
As Lynn said, the important thing to note is that we rely on the bib record import process & local system (Aleph) to automatically create many/most of the records (call#/item/order & indirectly invoice) that are connected to the bib, and that being able to identify the matching rules and behavior for when records are loaded is critical.
Hi Filip-
NCSU has quite a bit of our System policy tables (item types, loan rules, circ tables, etc. ) up on the web for everyone to ‘enjoy’.
You can find all sorts of information about the guts of the system setup here:
We also have a number of workflow diagrams - some of which are too NCSU specific to be of much use, but I thought that these automated record loading workflows might give you some sense of the types of processes & records we’re interacting with when we do batchloading
EBOOK APRV (1).pdf (72.4 KB)
EBOOK DDA (3).pdf (72.2 KB)
Promptcat APRV with shelfready.pdf (27.9 KB)
EBOOK FRM (1).pdf (25 KB)
Promptcat FRM w Shelfready0325.pdf (38.1 KB)
Lynn
Hi. Pasted below is a very high level description of a set of tech services related tools we use at Cornell called LS Tools. Adding it into the web discussion. Please let me know if these concepts are going to be discussed at a future meeting. I would like to participate. - Adam Chandler
LS Tools is a web-based user interface that pulls together a variety of custom scripts and tools, which staff in Library Technical Services rely on for daily batch processing operations.
LS Tools fall into three basic categories
• Get metadata from source (usually vendor), do some cleanup of metadata, and then import it into Voyager
• Pull data out from Voyager that meets criteria, manipulate data, and then send it somewhere
• Pull data out from Voyager that meets criteria, do something to it, and put it back in Voyager
We are not asking FOLIO to reproduce LS Tools exactly. Instead, we are asking FOLIO to provide us with what we need to re-produce LS Tools functionality:
We want FOLIO to provide us with the means of creating, managing, and executing our tools:
PS: I’ve been thinking also about how useful it would be to have the option to determine load behavior (e.g., overlay, match, reject, etc.) based on a field value in the incoming records. We can currently do this in Sierra, but only based on the Encoding Level (LDR position 17).
My overarching goal is to be able to protect either the entire record or certain fields once records have been sent out for authority control. There may be other ways to do this.
Almost all of the discussion so far has been with regards to batches of MARC records, that are either creating or updating locally-stored bib records, plus possibly orders and/or item records. YBP customers use this MARC-based workflow for approval purchases (P or E books arrive based on a profile, not a library’s order, and must be acquired, paid, cataloged, and made available all at point of order). This workflow is also used for DDA titles - the initial pool of “discovery” records, plus titles that are triggered for automatic purchase. Also for orders, using a pre- or post-order record from GOBI that creates bib and order in the library’s local system, followed by a cataloging record that updates the brief bib, creates/updates the item record, and either creates or links to electronic invoicing data. All of the above is data moving around in MARC records, usually via FTP.
At present, there is also an order API that handles post-order data (order in GOBI, copy that bib and order into library’s local system), but not pre-order data, approval/DDA data, final cataloging/item data, or invoice data.
And there is no API that sends orders from the library’s system to the vendor. Currently that is handled via EDI, e-mail, fax, or snail-mail.
And all of these workflows rely on locally-stored bibliographic records. For physical items, that makes sense. For electronic resources, if FOLIO libraries choose to move away from locally stored metadata and toward shared KB metadata, then that may require significant reworking of the above workflows, both on the part of the vendor and the library. If incoming vendor data needs to match to a KB record, the matchpoints may change (or the codex may help with that). If the vendor relies on supplying a final cataloging record to also supply a final call number, barcode number, and/or invoice matching data element, then that may disrupted.
None of this is insurmountable - just needs to be discussed/reviewed as part of the overall workflow rethinking in FOLIO.
Thanks,
A-M